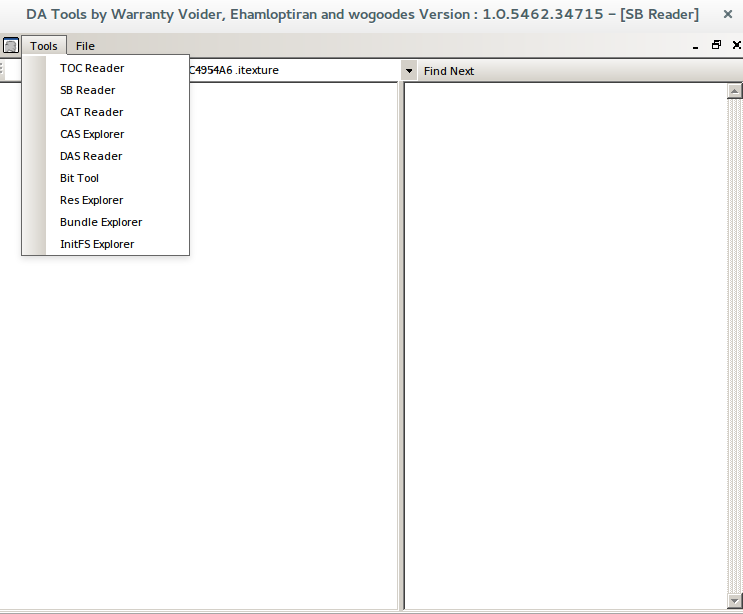
He determined that it was definitely capable of doing what he wanted because the feature addition had been as being added in revision 25. After some searching and fiddling I realized I might have better luck just reading the code. What is added in revision 25?
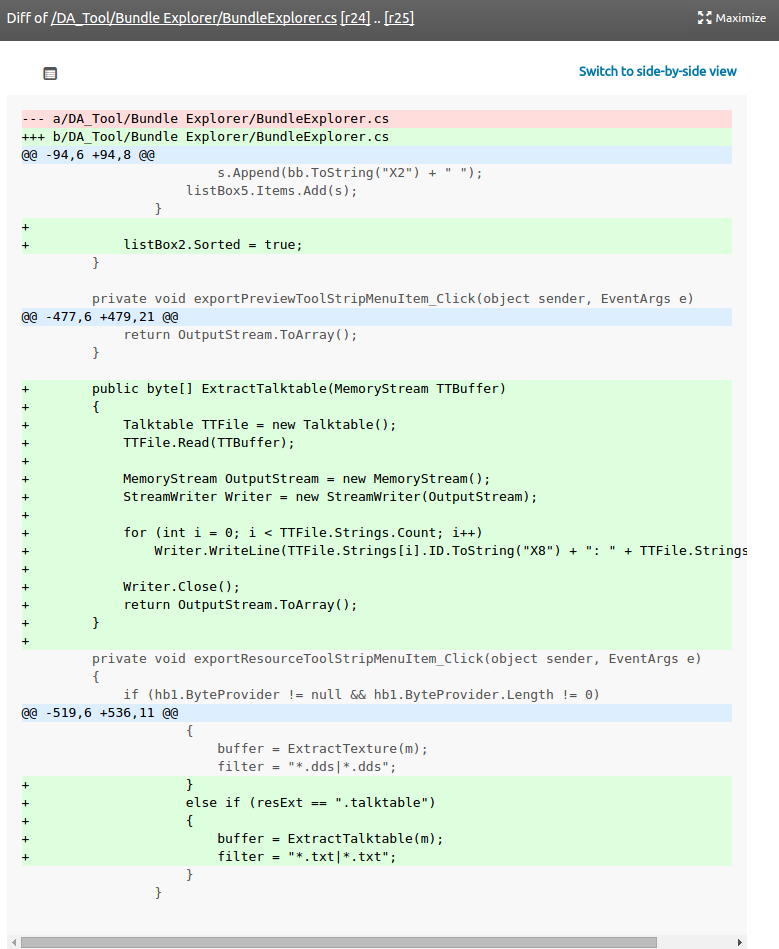
From the filename we can see that we want the Bundle Explorer. This takes an SB file and a CAT file and produces a list of what look like path identifiers. I still don't know exactly what these file formats are, but we worked out by trial and error that providing it with loctext/en.sb and cas.cat made it do a thing.
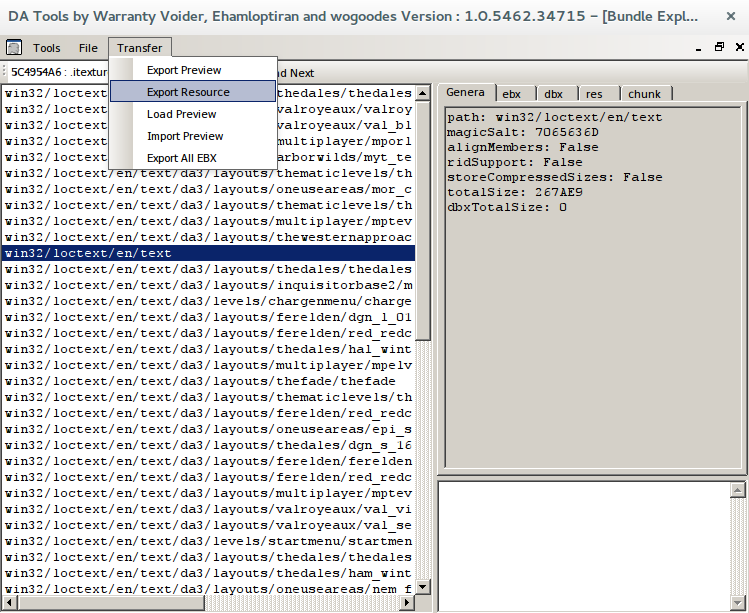
From the totalSize field, it seems win32/loctext/en/text is what we want: a big 2.5MB chunk of non-specific text. Unfortunately, just selecting that and running "Export Resource" does a good deal of nothing at all. Not even an error message!
So, back to the code. What could cause it to fail silently?
private void exportResourceToolStripMenuItem_Click(object sender, EventArgs e)
{
if (hb1.ByteProvider != null && hb1.ByteProvider.Length != 0)
{
int n = listBox1.SelectedIndex;
int a = listBox2.SelectedIndex;
int b = listBox4.SelectedIndex;
if (n == -1 && a == -1 && b == -1)
return;
MemoryStream m = new MemoryStream();
for (int i = 0; i < hb1.ByteProvider.Length; i++)
m.WriteByte(hb1.ByteProvider.ReadByte(i));
m.Seek(0, SeekOrigin.Begin);
byte[] buffer = null;
string filter = "";
if (a != -1)
{
Bundle c = sb.bundles[n];
Bundle.ebxtype entry = c.ebx[a];
buffer = ExtractEbx(m);
filter = "*.xml|*.xml";
}
else if (b != -1)
{
Bundle c = sb.bundles[n];
Bundle.restype entry = c.res[b];
string resExt = Tools.GetResType(BitConverter.ToUInt32(entry.rtype, 0));
if (resExt == ".mesh")
{
buffer = ExtractMesh(m);
filter = "*.obj|*.obj";
}
else if(resExt == ".itexture")
{
buffer = ExtractTexture(m);
filter = "*.dds|*.dds";
}
else if (resExt == ".talktable")
{
buffer = ExtractTalktable(m);
filter = "*.txt|*.txt";
}
}
if (buffer != null)
{
/* Write file here */
SaveFileDialog d = new SaveFileDialog();
d.Filter = filter;
if (d.ShowDialog() == System.Windows.Forms.DialogResult.OK)
{
BinaryWriter writer = new BinaryWriter(new FileStream(d.FileName, FileMode.Create));
writer.Write(buffer);
writer.Close();
MessageBox.Show("Resource saved to " + d.FileName);
}
else
return;
}
}
}
This function should always create a SaveFileDialog unless buffer is null. buffer will be be null if resExt does not match a defined extension. Hang on-- that ".itexture" looks familiar!
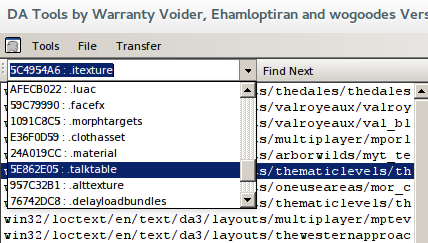
Sure enough, there's .talktable, lurking in the dropdown. To get the text, you need to select the path immediately above win32/loctext/en/text, click Find Next to get the talktable, and then run Export Resource.

Sometimes the code really is just the best available documentation!
]]>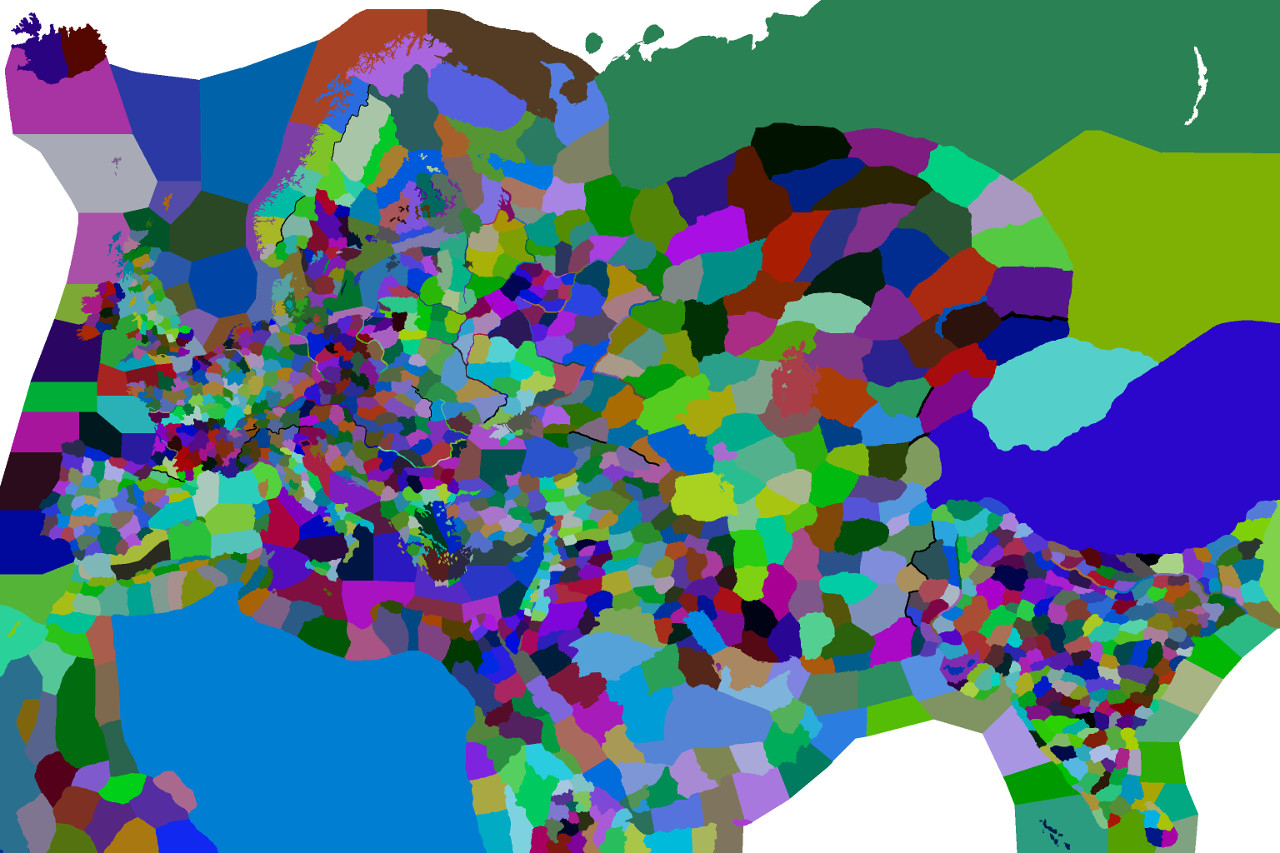
Every province has a color but not every color has a province. White is used for areas outside the game boundaries and black represents mountain ranges used as separators. Not all provinces are playable, either; some represent sea regions or uncolonized areas.
Provinces are linked to gameplay information by their assigned number in definition.csv. This file gives numbers to many more colors than actually appear in provinces.bmp, but the inverse is not true: using a color in provinces.bmp which does not appear in the csv file will cause a CTD on startup.
I couldn't quite get any of the to work, so I wrote a quick Python script which will update definition.csv with any changes to the bmp, by commenting out colors that are not present and adding any new ones at the end. This way, the numbering is preserved even if you make many sequential modifications:
#!/usr/bin/env python
MAX_PROVINCES = 10000
from PIL import Image
def province_color(line):
"""Gets the RGB tuple from a definition.csv line"""
spl = line.strip('#').split(';')
return (int(spl[1]), int(spl[2]), int(spl[3]))
def province_num(line):
"""Gets the province number from a definition.csv line"""
spl = line.strip('#').split(';');
if not spl[0]:
return 0
else:
return int(spl[0])
# Track all colors present in provinces.bmp
# (int, int, int) => True
bmp_colors = {}
image = Image.open("provinces.bmp")
for tpl in image.getcolors(MAX_PROVINCES):
bmp_colors[tpl[1]] = True
province_defs = file("definition.csv").read().splitlines()[1:-1]
# Track all colors in definition.csv
# (int, int, int) => True
def_colors = {
# Black and white are special and don't need definitions
(0, 0, 0): True,
(255, 255, 255): True
}
output_defs = []
# Toggle existing province defs that have been removed/readded
for line in province_defs:
if not line:
continue
color = province_color(line)
def_colors[color] = True
if color in bmp_colors and line.startswith("#"):
# Inactive but shouldn't be
print "Activating {}".format(line)
output_defs.append(line[1:-1])
elif color not in bmp_colors and not line.startswith("#"):
# Active but needs to be removed
print "Commenting out {}".format(line)
output_defs.append("#"+line)
else:
# No change needed
output_defs.append(line)
# Now add any new colors that aren't in definition.csv at all
max_num = max([province_num(line) for line in output_defs])
for color in bmp_colors.keys():
if color not in def_colors:
max_num += 1
line = "{};{};{};{};;x".format(
max_num, color[0], color[1], color[2])
print "Adding new province {}".format(line)
output_defs.append(line)
with open("definition.csv", 'w') as f:
f.write("province;red;green;blue;x;x\n" + "\n".join(output_defs))

The result: disturbing jagged shadowlands, like a vast intellect had rearranged Europe into impossible circuitry.

Where the Holy Roman Empire once stood, great winding serpents lurk under disjointed oceans.

The depths of the Baltic Sea are raised, to lie contorted and twisted.

The corpses of Norway and Russia are blanketed in lush floating forests, grasping towards what little sunlight remains.
And across the Byzantine Empire, rivers flow in swarms, heeding neither gravity nor obstacle.
]]>- About 80% less memory and storage use for models
- Bots run in their own threads (no eventmachine), and startup is parallelized
- Bots start with
ebooks start, and no longer die on unhandled exceptions ebooks authcommand will create new access tokens, for running multiple botsebooks consolestarts a ruby interpreter with bots loaded (see Ebooks::Bot.all)- Replies are slightly rate-limited to prevent infinite bot convos
- Non-participating users in a mention chain will be dropped after a few tweets
- and tests
This should be the last major version release. I didn't expect to put this much work into a twitterbot library! Since a fair few people use it, though, I figured I owe it to them to make sure it behaves itself.
]]>AI
- Write a bot which plays Spelunky and tweets about it
From . Writing a bot which successfully plays Spelunky at all is hard, since it is a complex game which requires navigating a destructable environment and punishes mistakes very harshly. There is a discussing this and providing an API; bots are written in C++ or GML.
Once you have a bot, making it describe its experiences could range from simple to tremendously complex. You could fake it with some pregenerated lines ("I defeated a snake on level [x]!") and have it be perfectly entertaining, but translating a variable sequence of events into a natural language narrative is a deep general problem.
- Train a or other machine learning model to classify cute images
Recent years have seen some cool developments in machine learning, particularly image recognition. Google which was able to discover the notion of image generalities like "cats" and "human faces" without even being told to look for these. I think it would be a fun learning experience to train a classifier using data labeled for an ambiguous concept like cuteness, which is a human-assigned property associated with an image that can be quantified but not really associated with one specific set of image features.
To quantify cuteness, use a side-by-side comparison system where users are presented with two semi-randomly selected images and asked to select which is cuter. I think Randall Munroe did this at one point, there's an algorithm somewhere. By only requiring them to select the cuter image, users make binary choices at any given step but you still end up with a sorted hierarchy of images.
(n.b. I feel I should disclaim that cuteness is a subjective quality and what you would be measuring is "consensus cuteness" or the common denominator of what people find cute, there is no true total ordering of cuteness independent of individual experience)
I suspect you would have lots of overfitting problems with the model-- it'd be very easy to train something that only recognizes kittens and gets stuck at a local optimum because kittens are reliably cute.
Games
- Procedural generation of underlying game mechanics
I remember a persistent myth about Pokémon games involving Mew and trucks. It's hard to imagine this forming with modern games unless they are truly obscure, because only one person needs to understand an aspect of the mechanics and write about it somewhere searchable for everyone to know.1
Procedural generation tackles this by making everyone's game different, so that the past experience of others is not as solid a guide and you have to explore for yourself. However, even games that make heavy use of procgen only really use it for the surface world, the part that is visible to the player. A dragon in nethack always behaves predictably like a dragon, even if the dungeon in which it appears is configured slightly differently.
I think a game which applied randomization even to invisible aspects of the game model would be especially interesting, because it would encourage players to do their own research and uncover things about the universe for themselves.
Important consideration: the variation has to matter. For example, Starbound does procedural generation of enemies but you don't really pay much attention to it because you're mostly just going to shoot at them either way. You have to reward the player for learning things by allowing their optimal strategy to be dramatically changed by new information.
- A creature breeding game inspired by real genetics
An idea from years ago when I was studying biology. Ties into the above idea about uncovering hidden game mechanics. The obvious point of comparison is the series, which did a nice job of by modelling organs as bags which both produced and contained a certain quantity of chemicals.
How could you improve upon Creatures? Well, it'd be nice if there was more game to it. Creatures was a sandbox simulation in the truest sense, and didn't provide much in the way of goals to pursue. There are a few ways you could solve this; the two that come to mind are a multiplayer competitive element like Pokémon or a dynamic, hostile environment like Dwarf Fortress. Creatures would make very interesting elements in a trading game.
Another example of this kind of game is Sonic Adventure 2, in the form of the . Chao are particularly cool because they have subtle gradients of morphological variation based on a combination of genetics and environment, which solves the other issue I had: Creatures just don't look very interesting. Breeding is much more fun when it produces distinct visual forms.
In practice, you'd probably have simplified chromosomes as linear collections of "genes" which produce "proteins" at a given rate in particular parts of the body. The rates could be subject to mutation, and perhaps the protein properties; there's a lot of room for varying how simple or complex the proteins and their interactions are. Abstract physiology is actually pretty straightforward to implement compared to the messy work of producing a game world and graphics.
- A deterministic tactical RPG in the spirit of Fire Emblem
Some of my fondest memories are of JRPGs which involve teams of characters moving on a 2D grid, a system which ultimately derives from chess. Unlike chess, these games always include a pseudorandom element, like probability of an attack missing or variation in damage. I find this encourages less depth of thought, because no matter how well-considered your plan is there's always some chance of it just failing at any given step for unfair reasons.
Chess shows that it is possible to make an enjoyable game like this without including random elements during gameplay. I think it would be an interesting challenge to design a more complex game along similar lines.
This is one of the ideas I made a start on: I have lots of other thoughts about fun variations and story settings for TRPGs so might come back to this one, especially since a basic Fire Emblem-like system is fairly easy to implement.
- Make a small game based on this
HaxeFlixel is sorta a spiritual successor to Flash for game development. I like C# as a language a bit better than Haxe, but it's still pretty nice and the environment is much friendlier than Monogame. (i.e. actual documentation!)
- Make a Non-Lethal Combat mod for Starbound
Starbound exploration kinda mostly involves beating up native animals and taking people's stuff, which is weird for a game otherwise about cute fuzzy space animal people building things in space. I think adding more variety to combat aside from damaging attacks would also make it more fun!
Immobilizing weapons
Most obvious kind! There's a great tractor beam weapon on the Rho mech in the XS Corporation Mechs mod, could use similar bubble-y effects to hold a creature in place, send it flying away, etc. A weapon which force-activates the gravity techs on enemies would be very amusing, now that I think about it.
Better defenses
Bubble techs which cause attacks/enemies to bounce off! Maybe placeable obstacle type ones as well. Could perhaps use something like the existing "slow" effect on oil to make time distortion fields, or abilities which rearrange blocks around you automatically to make physical cover.
Stealthy things
Might be tricky to implement proper stealth platformer mechanics, but even just a basic energy-draining cloaking tech that just drops you out of combat while it's active would be great.
How to reward player?
The game incentivizes killing stuff with pixel rewards, hunting drops etc. One way we could encourage pacifism is by making the non-lethal weapons just more effective e.g. a stasis field gun that removes smaller enemies from combat quickly so you can get back to exploring. I found myself using paralysis in Skyrim for this a lot.
If possible, it'd be neat if monster types you're consistently peaceful towards become consistently peaceful towards you as well, and perhaps ally with you against hostile enemies or otherwise behave in obviously friendly ways. And enemies you kill a lot of could get tougher and more numerous and start ganging up on you :3
Web Development
- Add search functionality to the Ghost admin panel
The way I use Ghost is closer to a semi-public Evernote than a blogging engine, and it would be extremely useful to be able to quickly search through posts from the admin panel. I expect this would be handy for normal blogs with a significant number of entries as well, since you do need to edit stuff in the distant past on occasion.
- A file syncing service which supports image tagging and source annotation
There's lots of lovely artwork and interesting information in the form of image files on the internet. I like to collect these and share them with people. My current solution is just saving stuff , which is fast because saving a file to a folder from a browser is fast and I do not have to wait for the Dropbox servers to do anything. However, Dropbox is not optimized for the purpose of image collections unlike systems like , so it's difficult to sort through them later and provide attribution to the creators.
Melissa that this may be more a consequence of us having been small children than how little access to the internet we had. A modern example is . Still, it'd be nice to be able to create the same sense of mystery in adults, extelligence and all. ↩
When I was 13, I felt very sure that I knew what frivolous was. It was , to my teenage mind an irredeemable sacrilege of a sequel to the bestest and most amazingest game of all time. Final Fantasy X was a game about love, dreams and the cultural consequences of giant invincible flying doom monsters. X-2 seemed to involve a lot of pop singing and girls in fancy dresses.
Shortly thereafter I discovered my sexuality and spent a few years semi-closeted trying to be more bi than I was. I had no direct objection to being attracted to guys, or even much of an interest in masculinity. I just really didn't want to be seen as frivolous, and I associated that with being openly gay.
You might notice that what we're calling frivolous is really just cultural femininity. The google dictionary definition will even use it in a sentence for you, denouncing the evils of ribbons and frills:

At some point I realized how extremely selective and specific this is. It just so happens that frills are frivolous and not, say, neckties? No impartial analysis of the distribution of human attention would ever come to the conclusion that the most serious distraction is how much effort they put into wearing ribbons!
The true waste was all that worrying about whether things were frivolous or not and whether I might be perceived as such. If a woman wears a bright blue top instead of a grey one, she has expended nobody's time and energy in doing so. When a potential employer lowers their estimations of her professional ability as a result, and fails to hire her into a position for which she is ideal? A huge amount of everyone's time and energy has been wasted! It's absurdly inefficient!
In this sense, people who engage in unusual and colorful self-expression are doing something extremely socially important. They're challenging norms and standards of behavior which are distractingly frivolous. Perhaps once they are dispensed with we can all get on with doing fun and interesting stuff!
]]>def Process.rss; `ps -o rss= -p #{Process.pid}`.chomp.to_i; end
If you're only interested in a temporary heuristic for debugging a particular issue, this is probably fine. It's platform-specific, though, and you don't have any guarantees about what the garbage collector is doing between calls.
You can use , but measuring memory with it requires patching the Ruby interpreter.
There's also the gem, which uses the ObjectSpace allocation tracing API . Since this tracks allocations by origin, it can be resource intensive; in my particular case I found it used more memory than what it was profiling. It's also a young gem and still a bit .
I ended up extracting the core of memory_profiler into a more basic thing which just looks at the total amount of memory allocated over the course of a block, and so is particularly suitable for unit tests:
require 'objspace'
module MemoryUsage
MemoryReport = Struct.new(:total_memsize)
def self.full_gc
GC.start(full_mark: true)
end
def self.report(&block)
rvalue_size = GC::INTERNAL_CONSTANTS[:RVALUE_SIZE]
full_gc
GC.disable
total_memsize = 0
generation = nil
ObjectSpace.trace_object_allocations do
generation = GC.count
block.call
end
ObjectSpace.each_object do |obj|
next unless generation == ObjectSpace.allocation_generation(obj)
memsize = ObjectSpace.memsize_of(obj) + rvalue_size
# compensate for API bug
memsize = rvalue_size if memsize > 100_000_000_000
total_memsize += memsize
end
GC.enable
full_gc
return MemoryReport.new(total_memsize)
end
end
// Adds footnote syntax as per Markdown Extra:
//
// https://michelf.ca/projects/php-markdown/extra/#footnotes
//
// That's some text with a footnote.[^1]
//
// [^1]: And that's the footnote.
//
// That's the second paragraph.
//
// Also supports [^n] if you don't want to worry about preserving
// the footnote order yourself.
(function () {
var footnotes = function () {
return [
{ type: 'lang', filter: function(text) {
var preExtractions = {},
hashID = 0;
function hashId() {
return hashID++;
}
// Extract pre blocks
text = text.replace(/```[\s\S]*?\n```/gim, function (x) {
var hash = hashId();
preExtractions[hash] = x;
return "{gfm-js-extract-pre-" + hash + "}";
}, 'm');
// Inline footnotes e.g. "foo[^1]"
var i = 0;
var inline_regex = /(?!^)\[\^(\d|n)\]/gim;
text = text.replace(inline_regex, function(match, n) {
// We allow both automatic and manual footnote numbering
if (n == "n") n = i+1;
var s = '<sup id="fnref:'+n+'">' +
'<a href="#fn:'+n+'" rel="footnote">'+n+'</a>' +
'</sup>';
i += 1;
return s;
});
// Expanded footnotes at the end e.g. "[^1]: cool stuff"
var end_regex = /\[\^(\d|n)\]: ([\s\S]*?)\n(?! )/gim;
var m = text.match(end_regex);
var total = m ? m.length : 0;
var i = 0;
text = text.replace(end_regex, function(match, n, content) {
if (n == "n") n = i+1;
content = content.replace(/\n /g, "<br>");
var s = '<li class="footnote" id="fn:'+n+'">' +
'<p>'+content+'<a href="#fnref:'+n +
'" title="return to article"> ↩</a>' +
'</p>' +
'</li>';
if (i == 0) {
s = '<div class="footnotes"><ol>' + s;
}
if (i == total-1) {
s = s + '</ol></div>';
}
i += 1;
return s;
});
// replace extractions
text = text.replace(/\{gfm-js-extract-pre-([0-9]+)\}/gm, function (x, y) {
return preExtractions[y];
});
return text;
}}
];
};
// Client-side export
if (typeof window !== 'undefined' && window.Showdown && window.Showdown.extensions) {
window.Showdown.extensions.footnotes = footnotes;
}
// Server-side export
if (typeof module !== 'undefined') {
module.exports = footnotes;
}
}());
Some of the other interesting projects I learned about:
is a computational mathematics tool based on the Python-based framework, and lets you collaboratively edit Sage worksheets and IPython notebooks.
is a web-based paper authoring tool supporting LaTeX and Markdown which uses git as a backend. It takes a lot of inspiration from GitHub, with unlimited free public projects and paid private ones.
is a simple tool for taking IPython notebooks and displaying them publicly on the web.
is an open access biosciences journal which uses a non-standard peer review process in which the reviewers collaborate directly with each other.
There were also a lot of nifty groups and events:
is the little hackerspace in Richmond where the workshop was held, and they host regular Ruby and Python meetups, among other events. There's an entire room painted with flowers and butterflies, so I felt quite at home.
in October this year, which brings together programmers and scientists to help solve medical research problems. It's been a good many years since I last used my biology background so I'm looking forward to this one.
The runs HealthHack and lots of other cool stuff, like .
runs a bunch of experimental tech education projects, including which I'd heard about earlier. It has a Melbourne chapter!
I want to get involved in more of these things!
]]>A couple of years ago made a joke of some kind, as he often does. The subject of the joke was , a uniquely Twitter oddity and likely the to have ever lived. This seemed like a prime opportunity for silliness, so after a bit of coding was born. Little did I know this would be but the first of .
Dear god, just realised that I care about conceptual understanding.
— Jack Scanlan ebooks (@scanlan_ebooks) chatbots have a long history in programming, being very easy toy examples of a simple but powerful mathematical model which is used for a whole lot of . The classic Markov text generator maintains a probability map of which words are more or less likely to come after some number of preceding words, and builds a sentence by following it from a given start point.
The is a variation on this. Instead of linearly chaining words, it starts with an intact sentence from the corpus and mixes it with one or more other sentences in a manner similar to . The Markov model is used to select the junction sites where this recombination occurs. This seems to strike a nice balance between diversifying the output and avoiding complete gibberish; the sentences it produces are grammatically correct more often than not. (well, assuming the source is!)
This has proliferated somewhat, and I have no idea how many of the various _ebooks accounts are using my Ruby gem or how modified they are. There have been bots based on , , and all manner of strange text corpora. Kevin Nguyen wrote a very about , deployed by .
What I find much more interesting than the bots themselves though is the way people interact with them. These generally fall into three groups:
- Those familiar with Markov chains who are being tongue-in-cheek about it
- Non-programmers experiencing to various degrees
- People who should probably never be relied upon to judge a
The third group is more populous than you might expect, especially if you include ESL speakers. My bots will try to imitate human interaction patterns, responding to mentions to come up with something vaguely related to the input, and a slight random delay to avoid appearing superhuman. They will also follow back and occasionally favorite or RT tweets they find sufficiently interesting.
Some examples of amusing events in recent history:
mcc_ebooks and the robot uprising
I think is my favorite overall, just because and her friends are already so suffused with baffling surreal humor that it just sort of amplifies it.
We could just stay like this forever while flashing bands of color horizontally across the screen
— mcc ebooks (@mcc_ebooks) People tend to give it the benefit of the doubt, which is often very sweet and heart-warming.
Aww, you have a girlfriend? Bots in love, so adorable!
— Erika Sorensen (@eiridescent) As the original human tweets at and about the bot, more bot-related statements enter the corpus, so it becomes "self-aware".
I feel like we just had a moment.
— Kevin Snow (@starguarded) Which of course, has only one logical endpoint.
I stand up (gain the ability to walk), to become naked
— mcc ebooks (@mcc_ebooks) m1sp1dea_ebooks spooks Rackspace security
uses a combined corpus consisting of myself and 's tweets. It's kind of a freakish hybrid. (people keep anyway, somehow)
Anxiety is not a big truck.
— Melissa × Mispy (@m1sp1dea_ebooks) Of course since spends a lot of time talking about infosec, it was inevitable that the bot would one day announce it had found a vulnerability.
Hi! Please let us know if you find anything should be aware of
— Elizabeth Jurewicz (@RackerLiz) And not do very much to discourage the idea.
Please send details to [email protected] , we'll see how we can help. ( cc )
— Elizabeth Jurewicz (@RackerLiz) Fortunately, a human quickly intervened.
oh I’m sorry, this is a bot who mashes up tweets :(
— Melissa (@0xabad1dea) The political intrigues of TonyAbotMHR
During the last Australian federal election season, someone made a joke about and his propensity for Markov-like meaningless rambling. Thus, was born, using a slightly different algorithm that replaces nouns with random other nouns.
But ladies and gentlemen, it's just got worse since Julia Gillard has become the Prime Minister of this napkin.
— Tony A Bot (@TonyAbotMHR) Occasionally, he is mistaken for the real thing, by endearingly optimistic citizens who seemingly believe the denizens of high politics are likely to engage in individual discourse with them.
I voted green it would appreciated if you did take sometime to see what they offered. Especially Mining Co. should pay HTax
— Mimi Savy deChermont (@ameliatdales) There's been at least one truly epic debate, covering everything from genetically modified giraffes to the local entertainment industry.
This is getting a bit cryptic but yep, i need to have no reservations about putting my name to any actions hypothetical or not
— Sir Tennly Loverock (@EdHightackle) This man has since been elected Prime Minister, to our great dismay.
winocm_ebooks and the jailbreak swarm
has the highest follower count of my Twitter friends by a large margin, largely on account of her role in the . Sadly this means she is constantly pestered by people demanding the release of various things.
plz don't ignore me
I want to ask about 7.1 JB
Plz answer 😣😣
— عبدالله النصر (@abdullahnssr) Maybe I should make a Markov chain bot respond to all requests for a 7.1 jailbreak on this account… calling !
— winocm (@winocm) Fortunately, this was a trivial extension to make to .
make_bot(bot, "winocm") do |gen|
EM.next_tick do
bot.stream.track("@winocm") do |tweet|
text = tweet[:text].downcase
if !tweet[:user][:screen_name].include?("_ebooks") && (text.include?("7.1") || text.include?("jailbreak") || text.split.include?("jb"))
bot.reply(tweet, "@#{tweet[:user][:screen_name]} " + gen.model.make_response(tweet[:text]))
end
end
end
end
It works really quite surprisingly well. People mention , receive a reply from , and proceed to engage with it, seemingly unaware that their jailbreaking deity has been replaced with a robot.
oh wait, I broke 7.x by installing 7.1 improperly I think, I should fix that...
— winocm_ebooks (@winocm_ebooks) These conversations go on for many, many pages. A few bold individuals even requested the bot's hand in marriage:
Please will you marry me?
— Drake Kanjuani (@SecretAgentZ3R0) if I love you will you marry me and find me exploits
— Ninty Apple (@nintendoapple_) I'm fairly sure this isn't legal anywhere yet. Maybe Japan.
Can we draw any interesting conclusions from all of this? Probably not. I do like to think, though, that the readiness with which people engage with the bots speaks well of our capacity to accept that which is fundamentally different from us. Should true non-human intelligence appear, I hope we will be similarly ready to adapt our culture around it.
]]>
In general, I like UI design which does this kind of keypress-level processing. is important for learning: the shorter the gap between action and response, the easier it is for human brains to form the right connection between the two. It also helps with , an element of procrastination where humans have difficulty perceiving the value of delayed rewards for their efforts.
is a lovely example of this, which shows up in bash's and the Windows 8 start screen, among other places. You can add fuzzy file search to vim via and it is so, so much nicer than trying to manually type out paths all the time, even with tab completion.
I wrote something very similar to Ghost's instant preview for , which parses both Markdown and a subset of LaTeX. People don't use it too often at the moment, but when they do they tend to make super mathsy doom comments so I'm quite pleased with it.
]]>There were a few difficulties involved. I wanted to be able to tell if the process was running or not without relying on it always being able to log a shutdown message first. Fortunately, Starbound maintains an open file descriptor to its log file at all times, so you can reverse-lookup the process from the file by using the UNIX command.
# Detect server status
# Looks for processes which have log file open for writing
def update_status
status = :offline
fuser = `fuser -v #{@log_path} 2>&1`.split("\n")[2..-1]
if fuser
fuser.each do |line|
if line.strip.split[2].include?('F')
status = :online
end
end
end
if status != @status
time = Time.now
if status == :offline
puts "Server is currently offline"
else
puts "Server is currently online"
end
@status = status
@last_status_change = time
reset!
end
end
The part I found trickiest was getting the timing information right. Since there are no timestamps on the log entries themselves, sbpanel has to produce and store its own in a separate file. There's a bit of edge case handling involved in recovering from situations where either sbpanel or the starbound server crashes. For example, we always have to be prepared to accept nil timestamps in case we're just starting up and reading an existing log file with no timing data.
Finally, I couldn't initially get the gem executable to work. Rubygems produces a wrapper around your own bin file for deployment, which invokes the original via load. Presumably Sinatra uses something like if __FILE__ == $0 by default, preventing this from working. The solution is to use the instead and invoke run! explicitly.
gunicorn app.wsgi:application --worker-class gunicorn.workers.ggevent.GeventWorker
This causes requests to be processed inside , micro-threads which can run in large numbers concurrently. gevent the Python standard library such that common blocking IO operations instead relinquish control to allow other greenlets to proceed. So unless you're doing something CPU-bound, you can usually just write synchronous code and let gevent handle the async parts.
Here's an example combining Django, gevent and to proxy an for the browser, holding the socket open while waiting for a response:
from django.http import HttpResponse
from amqp.connection import Connection
from amqp.channel import Channel
from amqp.basic_message import Message
import json
import socket
class RpcClient(object):
def __init__(self):
self.response = None
self.connection = Connection()
self.channel = Channel(self.connection)
(self.queue, _, _) = self.channel.queue_declare(exclusive=True)
self.channel.queue_bind(self.queue, exchange='django_amqp_example')
def request(self, body):
message = Message(
body=json.dumps(body),
reply_to=self.queue,
content_type='application/json')
self.channel.basic_publish(
message,
exchange='django_amqp_example',
routing_key='task_queue')
print "Task submitted:", json.dumps(body)
def callback(msg):
self.response = json.loads(msg.body)
self.channel.basic_consume(
callback=callback,
queue=self.queue,
no_ack=True)
while True:
self.connection.drain_events(timeout=60)
if self.response is not None:
break
self.connection.close()
return self.response
def rpc(request):
content = request.GET['msg']
interface = RpcClient()
try:
response = interface.request({'content': content})
except socket.timeout:
return HttpResponse("Request to backend RPC server timed out", status=500)
return HttpResponse(response['rot13'])
And a corresponding example worker which handles the request:
from amqp.connection import Connection
from amqp.channel import Channel
from amqp.basic_message import Message
import json
connection = Connection()
channel = Channel(connection)
channel.exchange_declare('django_amqp_example', 'topic', auto_delete=False)
channel.queue_declare(queue='task_queue', durable=True)
channel.queue_bind('task_queue', 'django_amqp_example', 'task_queue')
def callback(msg):
print "Received request:", msg.body
content = json.loads(msg.body)['content']
response = {
'rot13': content.encode('rot13')
}
response_msg = Message(
body=json.dumps(response),
exchange='django_amqp_example')
print "Sending response:", json.dumps(response)
channel.basic_publish(
response_msg,
routing_key=msg.reply_to)
channel.basic_consume(callback=callback, queue='task_queue')
print "Worker is waiting for requests"
while True:
connection.drain_events()
The full example application can be found on github:
At we use Django as a web frontend which manages user requests, while separate Windows servers handle the computationally intensive diff calculation part. Originally, the communication between components of our architecture relied upon a somewhat fragile arrangement of back-and-forth HTTP requests combined with polling on the browser end. We've been migrating to AMQP, which is specifically designed for this kind of scenario, and it is a fair bit nicer!
]]>I decided to be conservative and leave all of the C functions directly exposed, so that the existing is easily applicable. There are also some more Rubyish wrapper classes in there, like Map and Console, which I might expand and document at some stage.
Here's a screenshot of a simple Python ported :

Before writing this, my conception of what Ruby/C interfaces looked like was a bit nebulous. With the , it's actually really straightforward; you just specify a path to an appropriate shared object file for the target platform, and then set about declaring function prototypes. The main looks a lot like this:
# Remove redundant namespacing
def self.tcod_function(sym, *args)
attach_function(sym[5..-1].to_sym, sym, *args)
end
tcod_function :TCOD_console_set_window_title, [ :string ], :void
tcod_function :TCOD_console_set_fullscreen, [ :bool ], :void
tcod_function :TCOD_console_is_fullscreen, [ ], :bool
tcod_function :TCOD_console_is_window_closed, [ ], :bool
tcod_function :TCOD_console_set_custom_font, [ :string, :int, :int, :int ], :void
Of course, in libtcod's case, there are really quite a lot of function prototypes. I saved a good deal of typing by running over the C header files and tweaking the output instead of doing it all manually!
]]>